

Scraping Tool
The InData Scraping Tool gets data from the Internet Movie Database to extract and visualize correlations between keywords and titles.
The InData project investigates on the role and potentialities of data as activators in the design process identifying in speculative design and prototyping its application fields.
In the sphere of experimentation on interactive artifact, smart material and digital fabrication, design fiction and speculative design have a key role allowing designers to imagine and illustrate a future in which the artifact/technology/innovation is already present, is integrated and operates allowing also the exploration of assumptions, concepts and possible implications, including critical discussions that investigate on the complexity in social, cultural, ethical and environmental terms. The InDATA research project produces both a theoretical-practical framework and a platform that, starting from open access data, nourish the construction of contextual scenarios so to validate the existence of what is designed, triggering possible innovation that take advantage of hybrid and smart material, and new modes of interaction.
Year
2019
Funding Program
Politecnico di Milano | MiniFARB Funding Program
Project Team
InDATA team: Ilaria Mariani | Laura Varisco | Patrizia Bolzan | Stefano Parisi | Mila Stepanovic | Michele Invernizzi
Scraping Tool
Designer: Laura Varisco
Developer: DeepGlance S.r.l.

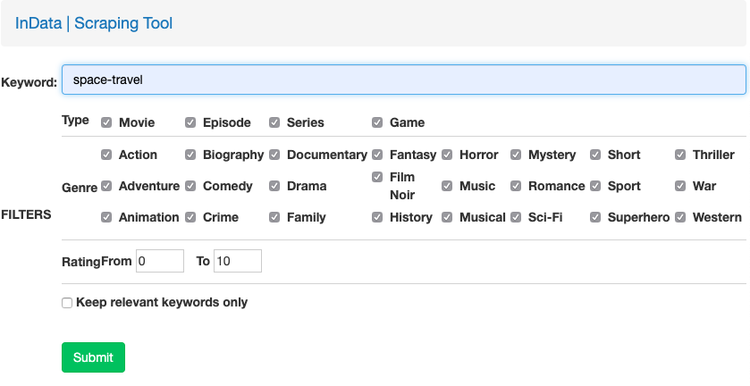
The InDATA Scraping Tool
The InData Scraping Tool is a web platform designed to support the envisioning of scenarios for students from various design disciplines. The tool takes advantage of the online repository IMDb.com that provides contents related to storytelling artifacts, and related user-generated metadata. It uses suggestions and inspirations coming from the collective intelligence so to nourish the designers’ creativity and lessen in individual biases and limits of knowledge – that come their subjective perspective that relies on socio-cultural backgrounds as source of knowledge.
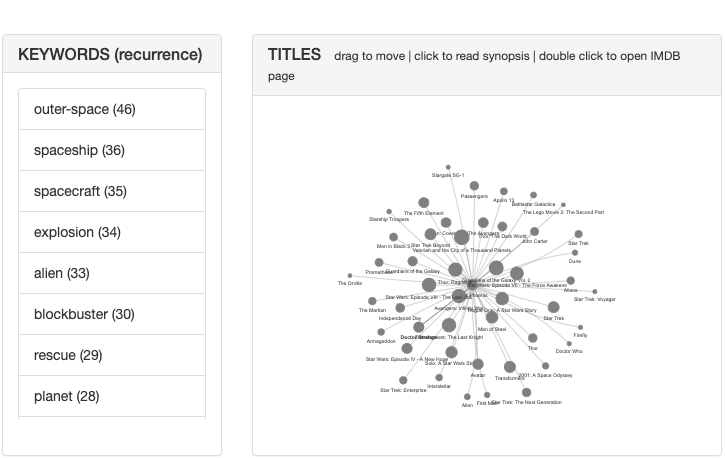
The keywords are listed according to recurrence among titles with the most recurrent keyword on top
The dimension of each title reflects the number of keywords it contains, and its proximity to the center is related to the number of common keywords with the most relevant title (in the center).
